
Novo modelo da DeepSeek reduz custos de inferência de IA
A DeepSeek acaba de lançar algo interessante: um novo modelo experimental, o V3.2-exp, que, segundo eles, pode reduzir seriamente os custos de inferência. Quer dizer, quem não quer economizar dinheiro, certo? Especialmente quando estamos falando dos altos custos de servidor para executar modelos de IA.
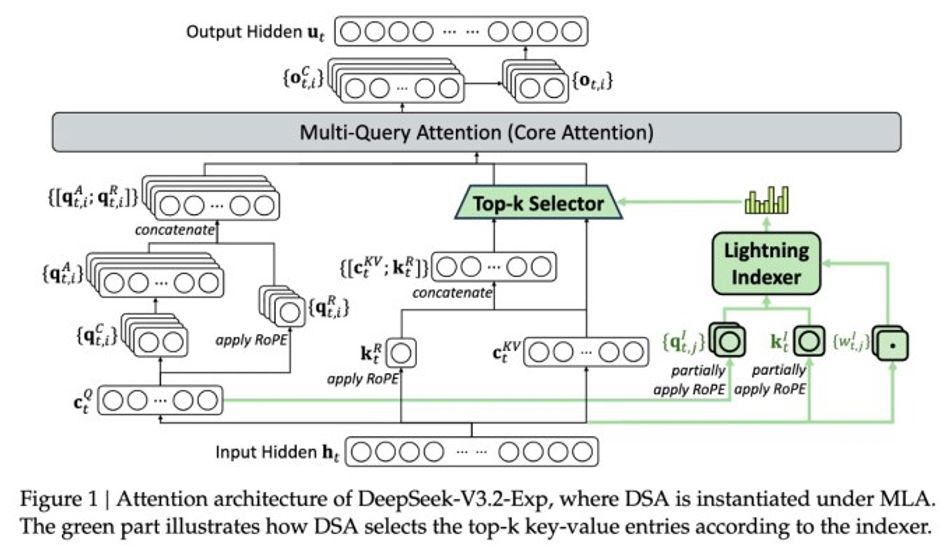
A verdadeira mágica por trás deste modelo é algo que eles estão chamando de DeepSeek Sparse Attention. Agora, não vou te entediar com todos os detalhes técnicos, mas o ponto principal é que ele foi projetado para priorizar as partes mais importantes da janela de contexto. Pense nisso assim: imagine ler um livro longo, mas apenas se concentrando nos parágrafos-chave que impulsionam a história. É essencialmente isso que este sistema faz, o que permite lidar com contextos longos sem sobrecarregar o servidor.
O que é realmente empolgante é a potencial economia de custos. Os testes preliminares da DeepSeek sugerem que uma simples chamada de API pode custar até metade do preço em situações de contexto longo. Isso é muito importante! Claro, precisaremos de mais testes para confirmar essas alegações, mas o fato de o modelo ser de código aberto e estar disponível no Hugging Face significa que pesquisadores independentes podem entrar e experimentar.
É interessante ver a DeepSeek, uma empresa sediada na China, continuar a ultrapassar os limites da eficiência da IA. Embora seu modelo R1 anterior não tenha exatamente desencadeado uma revolução, esta nova abordagem de atenção esparsa pode oferecer informações valiosas para manter os custos de inferência sob controle. E, sejamos honestos, isso é algo que beneficia todos no espaço da IA.
1 Imagem de DeepSeek V3.2-exp:
Fonte: TechCrunch